266일차 스크래피(Scrapy) - 지마켓(Gmarket) 크롤링
2021. 9. 21. 20:14ㆍDiary/201~300
크롤러(spider) 작성
1. items.py 작성
- 크롤링하고자 하는 데이터를 아이템(item)으로 선언해줘야 함
- 클래스를 만들고, scrapy.item을 상속받고, 아이템 이름을 만들고, scrapy.Field()를 넣어줘야 함.
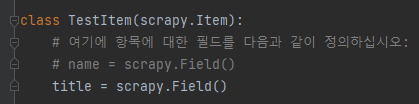
2. gmarket.py 수정
- yield 명령어로 아이템(item)에 저장할 수 있다.
- 아이템 클래스 생성 및 아이템 저장
선언
from 프로젝트이름.items import 아이템클래스명
클래스 생성
item = 아이템클래스명()
아이템 저장
item['아이템명'] = 아이템데이터
yield item
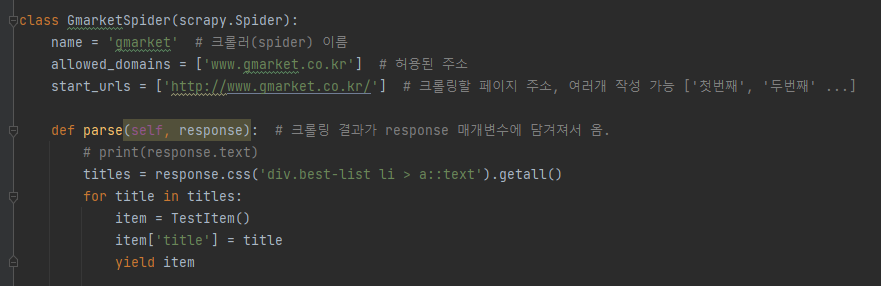
3. 데이터 포맷으로 아이템 저장
- csv, xml, json 포맷
- scrapy crawl {크롤러명} -o {저장할 파일명} -t {저장포맷}
# 한글 문자가 깨질 경우
- setting.py에 추가
FEED_EXPORT_ENCODING = 'utf-8'
- gmarket.py
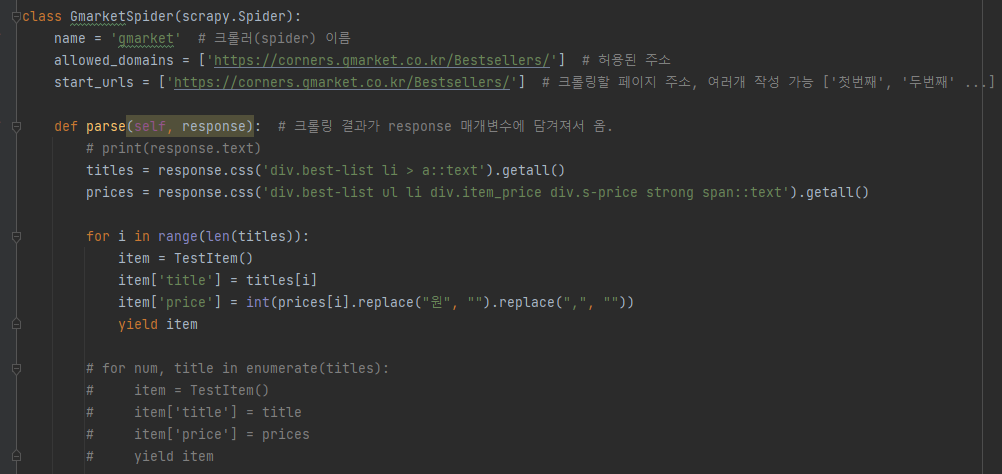
- items.py

- json 파일로 저장

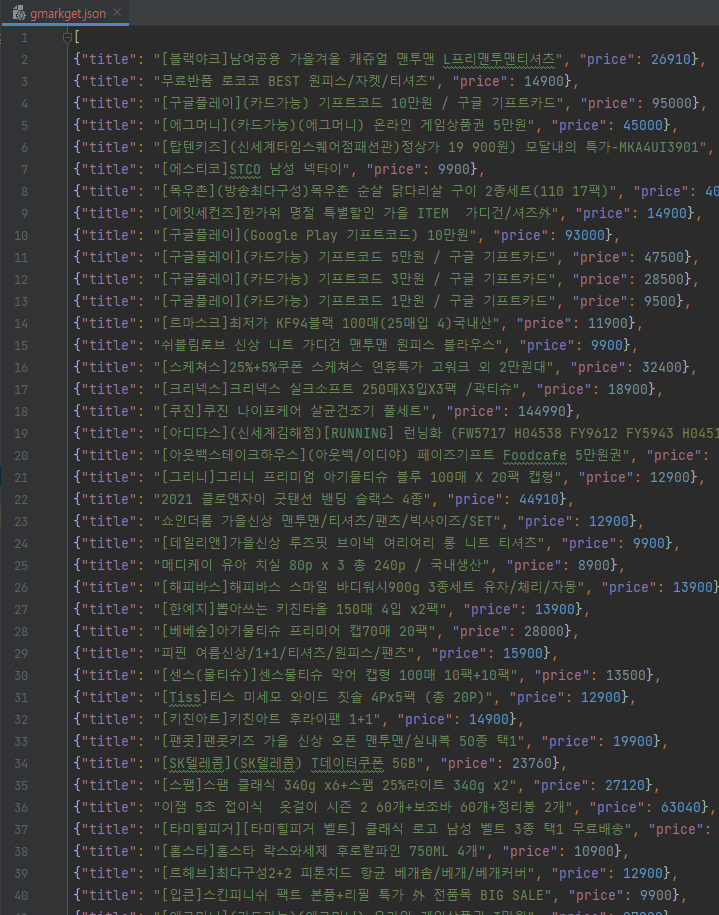
아이템 데이터 후처리하기 : 파이프라인(pipelines)
- 일부 아이템은 저장하지 않거나
- 중복되는 아이템을 저장하지 않거나
- 데이터베이스등에 저장하거나
- 특별한 포맷으로 아이템을 저장하고 싶거나
-> 아이템이 저장되려 할 때마다, pipelines.py의 process_item 함수를 호출한다.
1. settings.py 수정
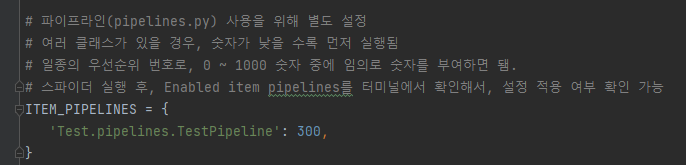
- 여러 클래스가 있을 경우, 숫자가 낮을 수록 먼저 실행됨
- 일종의 우선순위 번호로, 0 ~ 1000 숫자 중에 임의로 숫자를 부여하면 됌.
- 스파이더 실행 후, Enabled item pipelines를 터미널에서 확인해서, 설정 적용 여부 확인 가능
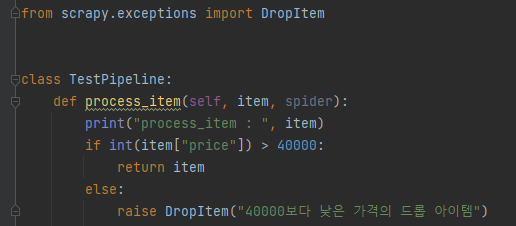
2. pipelines.py 수정
각 아이템 생성 시, pipelines.py에 있는 process_item 함수를 거쳐가게 되어 있다.
필요한 아이템만 return 해주고, 필터링할 아이템은 DropItem을 통해, 더이상의 아이템 처리를 멈추게 해줘야 한다.
3. json파일로 저장 후 확인
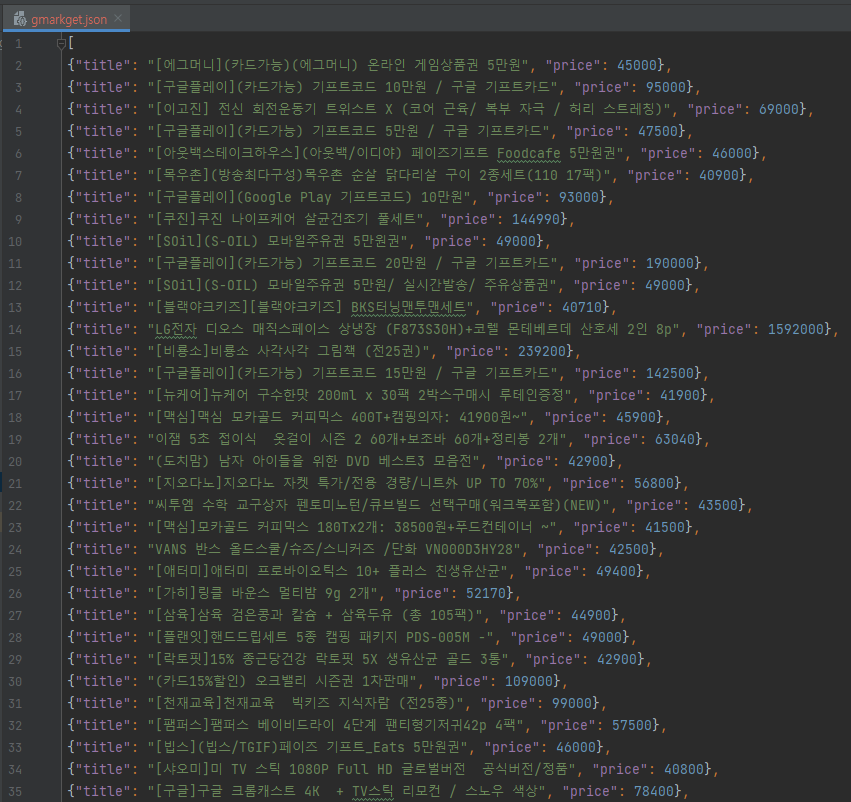
40000원 이상의 아이템만 잘 가져와졌다~!
'Diary > 201~300' 카테고리의 다른 글
| 268일차 셀레니움(Selenium) - 나무위키 크롤링 (1) (0) | 2021.09.23 |
|---|---|
| 267일차 스크래피(Scrapy) - 지마켓(Gmarket) 전체 카테고리 상품 크롤링 (0) | 2021.09.22 |
| 265일차 스크래피(Scrapy) - 환경 설정 및 기초 (0) | 2021.09.20 |
| 264일차 셀레니움(Selenium) - XPATH를 활용한 페이스북(Facebook), 트위터(Twitter) 로그인 (0) | 2021.09.19 |
| 263일차 셀레니움(Selenium) - 다음 뉴스 댓글 크롤링 (0) | 2021.09.18 |