2021. 9. 20. 18:27ㆍDiary/201~300
스크래피(Scrapy)
# 참고 : 스크래피(Scrapy)는 프레임워크이다. (사용방법 숙지하고 규칙에 따라줘야함)
특징
- 크롤링을 좀 더 안정적으로 할 수 있다. -> 스크래피 내부에서 다양한 안전장치가 있다.
- 크롤링을 좀 더 빠르게 할 수 있다. -> 크롤링 프로그램을 동시에 여러개 실행시켜서 많은 양의 데이터 크롤링 시, 시간을 단축시킬 수 있다.
- 다양한 크롤링 관련 기능 -> 크롤링한 데이터를 다양한 포맷으로 저장 가능하다.
사용방법
- 실제 크롤링할 스파이더(spider, scrapy 기반 크롤링 프로그램) 생성
- 크롤링할 사이트(시작점)와 크롤링할 아이템(item)에 대한 selector 설정
- 크롤러 실행
설치
- pip install scrapy
또는
- pip install --upgrade setuptools
- pip install pypiwin32
- pip install twisted[tls]
그래도 안된다면
- https://visualstudio.microsoft.com/ko/downloads/
Visual Studio Tools 다운로드 - Windows, Mac, Linux용 무료 설치
Visual Studio IDE 또는 VS Code를 무료로 다운로드하세요. Windows 또는 Mac에서 Visual Studio Professional 또는 Enterprise Edition을 사용해 보세요.
visualstudio.microsoft.com
스크래피 프로젝트 생성
- scrapy startproject {프로젝트이름}


- scrapy.cfg : 구성 파일 배포
- Test : 프로젝트의 Python 모듈, 여기에서 코드를 가져옵니다.
- items.py : 프로젝트 항목 정의 파일
- pipelines.py : 프로젝트 파이프라인 파일
- settings.py : 프로젝트 설정 파일
- spiders : 나중에 스파이더를 넣을 디렉토리
크롤러(spider) 작성
# Scrapy 프로젝트인 ../Test/Test/ 폴더에서 명령어를 입력해야함.
- scrapy genspider {크롤러이름} {크롤링페이지주소}


크롤러(spider) 실행
- scrapy crawl gmarket
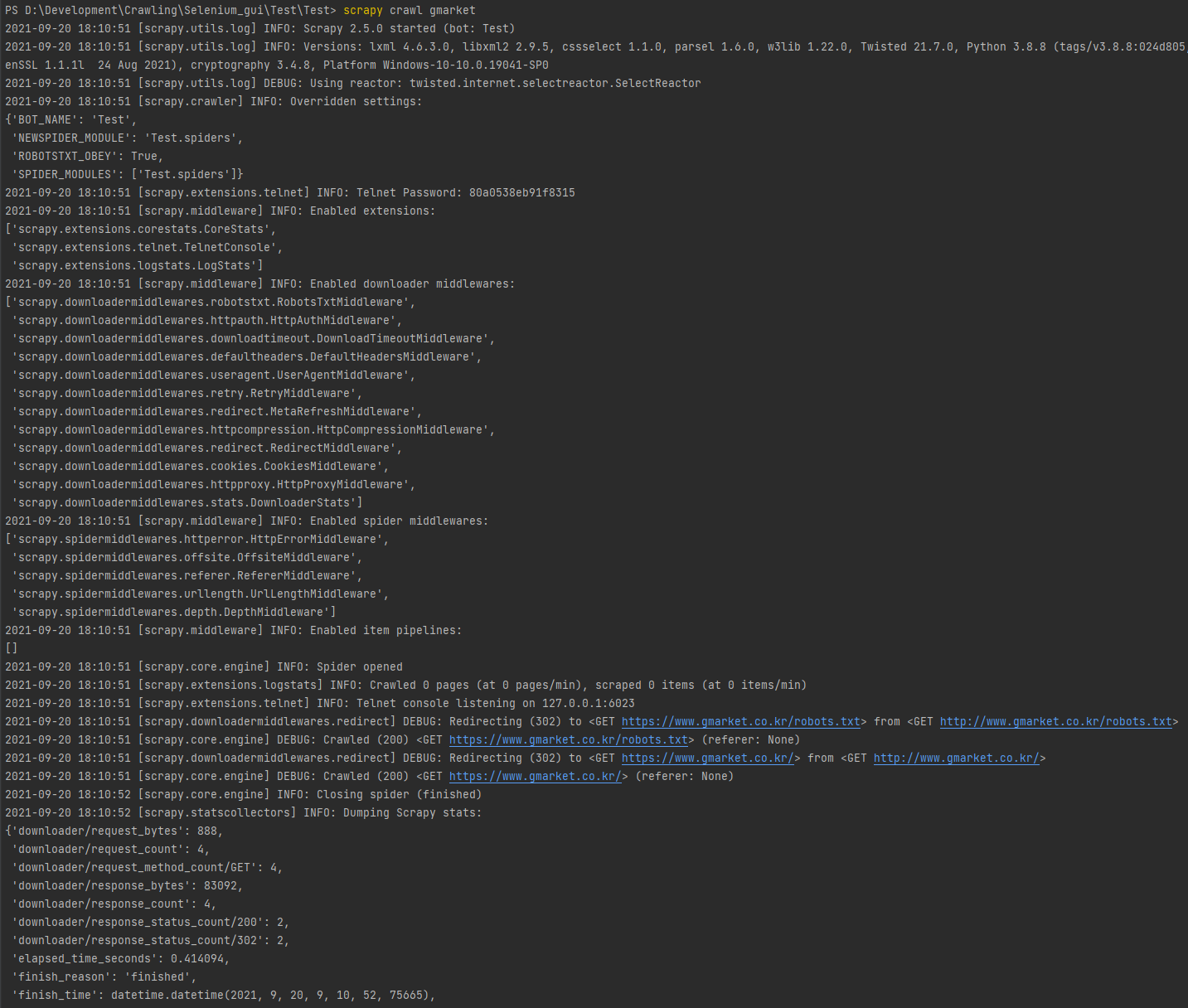
내장 함수인 parse의 response로 값이 떨어진다.
확인해보자.


스크래피 쉘 ( Scrapy Shell )
- scrapy shell '크롤링할 페이지 주소'
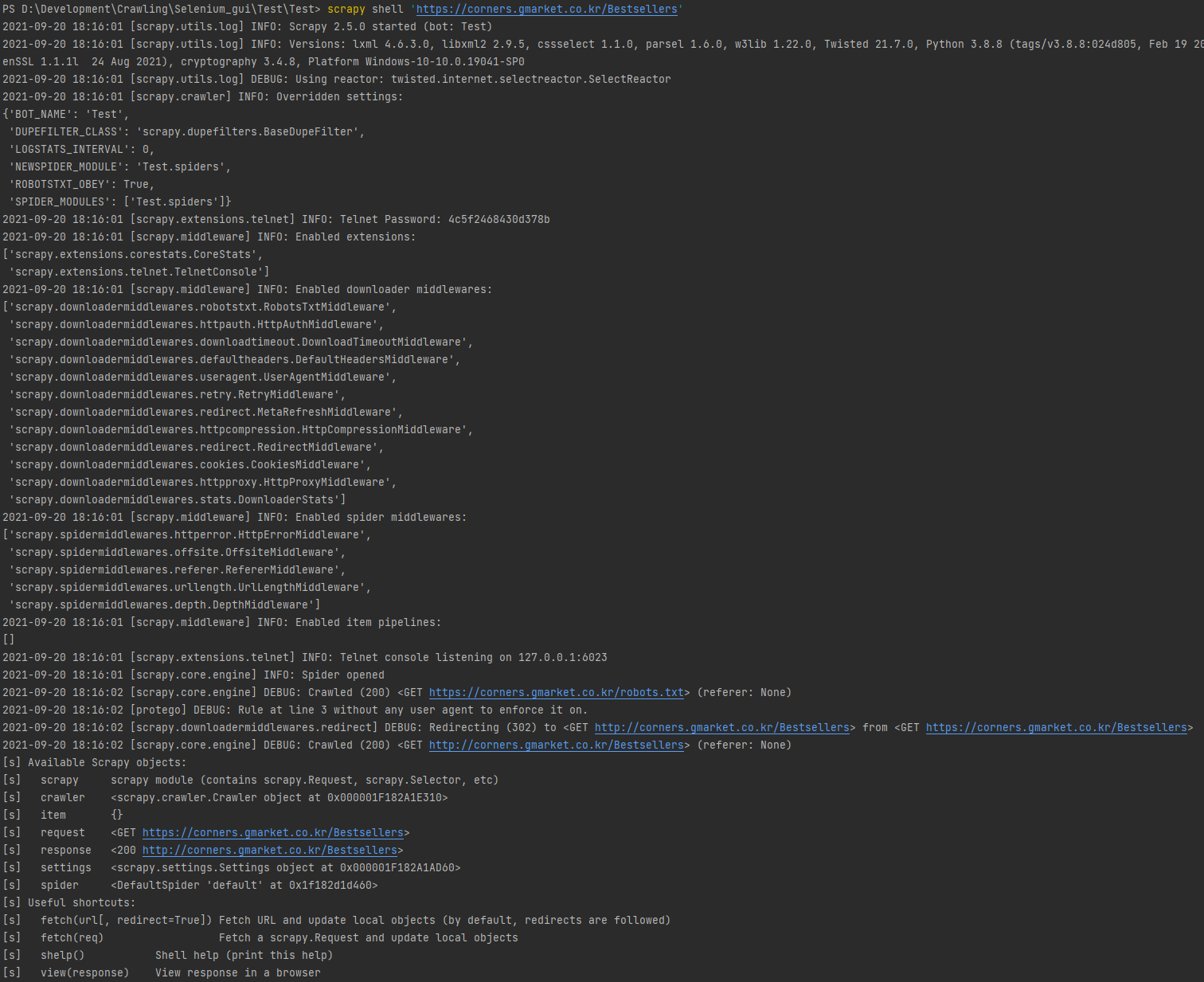
명령어
- exit 또는 Ctrl + Z : 종료
- view(response) : 크롤링한 페이지를 웹 브라우저를 통해 확인하기 (캐시에 저장된 웹페이지가 열림)
- response.css(' CSS 셀렉터 값 ').get() : 최초의 데이터만 가져옴
- response.css(' CSS 셀렉터 값 ').getall() : 전체 데이터를 가져옴
- response.xpath(' XPATH ').get()
- response.xpath(' XPATH ').getall()


정규 표현식 사용
- response.css( ' CSS 셀렉터 ' )[인덱스].re( ' 정규 표현식 ' )

'Diary > 201~300' 카테고리의 다른 글
| 267일차 스크래피(Scrapy) - 지마켓(Gmarket) 전체 카테고리 상품 크롤링 (0) | 2021.09.22 |
|---|---|
| 266일차 스크래피(Scrapy) - 지마켓(Gmarket) 크롤링 (0) | 2021.09.21 |
| 264일차 셀레니움(Selenium) - XPATH를 활용한 페이스북(Facebook), 트위터(Twitter) 로그인 (0) | 2021.09.19 |
| 263일차 셀레니움(Selenium) - 다음 뉴스 댓글 크롤링 (0) | 2021.09.18 |
| 262일차 셀레니움(Selenium) - 다음 뉴스 크롤링 (0) | 2021.09.17 |